
________________________________
From: Andries van der Leij Sent: Wednesday, December 06, 2006 5:59 PM To: 'freesurfer@nmr.mgh.harvard.edu' Subject: Freesurfer and Grid computing
Dear Freesurfer community,
I'm a PHD student at the university of Amsterdam and I'm currently investigating the possibilities to streamline our MRI data processing stream. Next summer we'll obtain a research-only scanner. I'm trying to push the group to also invest in computing power and am currently investigating the applications that researchers will most probably use.
I came across a project of the group of Cohen at UCLA. They have configured a Apple (unix) grid and have proposed a more or less standard setup specially designed for MRI analyses:
http://airto.bmap.ucla.edu/mt-static/NICluster/archives/2005/06/welcome. html
It is my understanding that one of the members has rewritten the FSL code which allow distributed parallel processing in a Grid. See the benchmarks here:
http://airto.bmap.ucla.edu/bmcweb/bmc_bios/MarkCohen/Apple/Benchmarks.ht m
My question is fairly simple: Are similar steps taken in the Freesurfer community? I have no experience with this app myself, but it is my understanding that Freesurfer consumes a lot of resources.
Thank you very much in advance,
Andries van der Leij

Andries,
I am not aware of usage of Freesurfer in a (Sun) Grid Engine environment (such as that used by the Cohen group at UCLA).
However, here at the MGH/MIT/HMS Martinos Center we use a cluster of some 100+ nodes configured with Linux Centos 4, and governed by PBS (Portable Batch System). Researchers here often conduct studies with dozens to hundreds of brains, and for each subject, an instance of Freesurfer's 'recon-all -s <subject> -all' script is submitted to the batch system, which, under the hood, gets submitted to one computing node. Thus, several dozen brains can be processed in a day (and a half).
Freesurfer does not currently support fine-grain parallelism. Some coarse-grain parallelism, whereby each brain hemisphere is processed independently (benefiting multiprocessor nodes) is possible, but not currently implemented in our 'recon-all' script, as the error handling and logging for doing so is somewhat tricky (and so this feature is in- the-works-but-not-anytime-soon).
In short, if you plan on using Freesurfer in studies with large numbers of subjects, I would recommend some kind of computing cluster, and some fairly simple batch software (like PBS) should be sufficient. For instance, I know of one group that has successfully run Freesurfer on their Altix Itanium Linux cluster.
Groetjes,
Nick
On Wed, 2006-12-06 at 18:44 +0100, Andries van der Leij wrote:
From: Andries van der Leij Sent: Wednesday, December 06, 2006 5:59 PM To: 'freesurfer@nmr.mgh.harvard.edu' Subject: Freesurfer and Grid computing
Dear Freesurfer community,
I’m a PHD student at the university of Amsterdam and I’m currently investigating the possibilities to streamline our MRI data processing stream. Next summer we’ll obtain a research-only scanner. I’m trying to push the group to also invest in computing power and am currently investigating the applications that researchers will most probably use.
I came across a project of the group of Cohen at UCLA. They have configured a Apple (unix) grid and have proposed a more or less standard setup specially designed for MRI analyses:
http://airto.bmap.ucla.edu/mt- static/NICluster/archives/2005/06/welcome.html
It is my understanding that one of the members has rewritten the FSL code which allow distributed parallel processing in a Grid. See the benchmarks here:
http://airto.bmap.ucla.edu/bmcweb/bmc_bios/MarkCohen/Apple/Benchmarks.htm
My question is fairly simple: Are similar steps taken in the Freesurfer community? I have no experience with this app myself, but it is my understanding that Freesurfer consumes a lot of resources.
Thank you very much in advance,
Andries van der Leij
Freesurfer mailing list Freesurfer@nmr.mgh.harvard.edu https://mail.nmr.mgh.harvard.edu/mailman/listinfo/freesurfer

-----BEGIN PGP SIGNED MESSAGE----- Hash: SHA1
We have a SUN grid system at UCSF. I have some shell scripts for using freesurfer on this type of grid. As said earlier, freesurfer does not contain multi-threaded programs. Use of the grid is simply to run multiple instances of freesurfer programs on different processing nodes (computers). The grid is managed by scheduling programs. We submit jobs to those scheduling programs (qsub in our case). My simple solution consists of two parts, a) a subject specific script to run recon-all (only if necessary) and b) another script to find and loop over subjects and submit those jobs to the grid.
a) freesurfer_recon_script.csh (Note that all of my freesurfer environment variables are setup in ~/.cshrc and this environment is configured to work correctly on all nodes of the grid system, providing the NFS disk mapping is working.)
############### CUT BELOW HERE ################# #!/bin/csh
echo $0 $1
cd $SUBJECTS_DIR pwd
if ( "$1" == "" ) then echo echo "Missing <subjID>, please use" echo "$0 <subjID>" echo exit 1 endif
if ( -d $1 ) then
echo $1
# has this been done already? if ( -s $1/surf/lh.pial && -s $1/surf/rh.pial ) then echo echo "The pial surfaces already exist:" echo ls -l $1/surf/* echo else recon-all -subjid $1 -all endif endif ############### CUT ABOVE HERE #################
b) ~/bin/freesurfer_recon_gridSubmit.csh ############### CUT BELOW HERE ################# #!/bin/csh
cd $SUBJECTS_DIR
foreach sub ( `ls -d ucsf_??` )
echo $sub
# has this been done already? if ( -s $1/surf/lh.pial && -s $1/surf/rh.pial ) then echo echo "The pial surfaces already exist." echo else qsub -q dnl.q -l arch=lx24-x86 ~/bin/freesurfer_recon_script.csh $sub & endif end ############### CUT ABOVE HERE #################
It's a little bit clumsy this way, but qsub is not really intelligent about handling job specifications (or I am too stupid to figure out how to get it all into one script!), so I ask it to run a shell script.
Best, Darren
Andries van der Leij wrote:
*From:* Andries van der Leij *Sent:* Wednesday, December 06, 2006 5:59 PM *To:* 'freesurfer@nmr.mgh.harvard.edu' *Subject:* Freesurfer and Grid computing
Dear Freesurfer community,
I?m a PHD student at the university of Amsterdam and I?m currently investigating the possibilities to streamline our MRI data processing stream. Next summer we?ll obtain a research-only scanner. I?m trying to push the group to also invest in computing power and am currently investigating the applications that researchers will most probably use.
I came across a project of the group of Cohen at UCLA. They have configured a Apple (unix) grid and have proposed a more or less standard setup specially designed for MRI analyses:
http://airto.bmap.ucla.edu/mt-static/NICluster/archives/2005/06/welcome.html
It is my understanding that one of the members has rewritten the FSL code which allow distributed parallel processing in a Grid. See the benchmarks here:
http://airto.bmap.ucla.edu/bmcweb/bmc_bios/MarkCohen/Apple/Benchmarks.htm
My question is fairly simple: Are similar steps taken in the Freesurfer community? I have no experience with this app myself, but it is my understanding that Freesurfer consumes a lot of resources.
Thank you very much in advance,
Andries van der Leij
Freesurfer mailing list Freesurfer@nmr.mgh.harvard.edu https://mail.nmr.mgh.harvard.edu/mailman/listinfo/freesurfer
- --
Darren L. Weber, Ph.D. Postdoctoral Scholar
Dynamic Neuroimaging Laboratory, UCSF Department of Radiology, 185 Berry Street, Suite 350, Box 0946, San Francisco, CA 94107, USA.
Tel: +1 415 353-9444 Fax: +1 415 353-9421 www: http://dnl.ucsf.edu/users/dweber
"To explicate the uses of the brain seems as difficult a task as to paint the soul, of which it is commonly said, that it understands all things but itself." Thomas Willis (The Anatomy of the Brain and Nerves, 1664)
Hi Darren,Nick and freesurfers,
Thanks very much for your replies! I've discussed this and have a couple of questions. I would be very glad if you could help me out.
I'm currently talking with my group to decide where to go. Like I said, we will get a research-only 3T scanner, which (if used as much as we hope) will deliver about 20 GB of raw data each week. We need to think of a solid processing and storage pipeline in order to be able to do something with the data ;)
We discussed this and are trying to come up with a good solution, both storage and analyses-wise. One solution for the enhancement of the analyses would be to buy a couple of solid workstations. The other would be a grid solution. The main problem isn't as much finance as it is manpower. No current member of the faculty has the time to invest in setting up and maintaining a grid if that will be a very difficult task to do. Hopefully we will get the money to hire an ICT person to do this. However, this is not certain. So I have a question concerning the difficulty of setting up the grid like proposed by Nick: semi-parallel in the sense that different commands of a batch are distributed to different nodes. We are wondering just how difficult this is.
I address this question to both of you. Darren: you have SUN grid and Nick you have something like SUN grid. Nick, you state:
<snip> You are on-track with the first scenario. If you have the technical skills and time to install the Sun Grid Engine, or PBS (which does nearly the same thing), then the batch interface will be easy for others to submit as many 'recon-all' instances as they want and will handle balancing. Once a batch system is setup, you can expect to have to spend some time maintaining the system (help-line, monitoring for stalled jobs, failed nodes, or failed disks, etc). You could also write your own scripts implementing a simple batch system, if you don't mind semi-manually tracking the resources, and if you will oversee it or use it yourself, and keep it small-scale. </snip>
The issue of course is this:
1. Just how much technical skills and time does the installation and maintenance of a Grid cost? It is my impression that the implementation of the SUN grid is not that hard. But I'm always an optimist if it comes to computers, although at times this has proven to be a great overestimation of my own knowledge and skills.
2. How 'intuitive' is the usage of a batch system like SUN grid and how stable is it? That is: given that we write guidelines, howtos, and set up a Wiki, how difficult will drag&drop type users will be able to work with such a system?
The final maintenance issues that Nick addresses concerns failure.
3. Hardware failure: freezing nodes and disk failures I expect to cost as much time as it will cost when we buy individual workstations, Maybe even less?
4. Software failure. Maybe I'm way off here, but it's my impression that the host running the batch system uploads the input data from a central server to a node, which analyses the data and then downloads the resulting output again, deleting the data on the node. If this is correct and if a single job fails, do you have to manually delete working data on a node?
I hope you can help me out with this.
Thank you!
Andries
-----Original Message----- From: Darren Weber [mailto:dweber@radmail.ucsf.edu] Sent: Friday, December 08, 2006 3:33 AM To: Andries van der Leij Cc: freesurfer@nmr.mgh.harvard.edu Subject: Re: [Freesurfer] Freesurfer and Grid computing
-----BEGIN PGP SIGNED MESSAGE----- Hash: SHA1
We have a SUN grid system at UCSF. I have some shell scripts for using freesurfer on this type of grid. As said earlier, freesurfer does not contain multi-threaded programs. Use of the grid is simply to run multiple instances of freesurfer programs on different processing nodes (computers). The grid is managed by scheduling programs. We submit jobs to those scheduling programs (qsub in our case). My simple solution consists of two parts, a) a subject specific script to run recon-all (only if necessary) and b) another script to find and loop over subjects and submit those jobs to the grid.
a) freesurfer_recon_script.csh (Note that all of my freesurfer environment variables are setup in ~/.cshrc and this environment is configured to work correctly on all nodes of the grid system, providing the NFS disk mapping is working.)
############### CUT BELOW HERE ################# #!/bin/csh
echo $0 $1
cd $SUBJECTS_DIR pwd
if ( "$1" == "" ) then echo echo "Missing <subjID>, please use" echo "$0 <subjID>" echo exit 1 endif
if ( -d $1 ) then
echo $1
# has this been done already? if ( -s $1/surf/lh.pial && -s $1/surf/rh.pial ) then echo echo "The pial surfaces already exist:" echo ls -l $1/surf/* echo else recon-all -subjid $1 -all endif endif ############### CUT ABOVE HERE #################
b) ~/bin/freesurfer_recon_gridSubmit.csh ############### CUT BELOW HERE ################# #!/bin/csh
cd $SUBJECTS_DIR
foreach sub ( `ls -d ucsf_??` )
echo $sub
# has this been done already? if ( -s $1/surf/lh.pial && -s $1/surf/rh.pial ) then echo echo "The pial surfaces already exist." echo else qsub -q dnl.q -l arch=lx24-x86 ~/bin/freesurfer_recon_script.csh $sub & endif end ############### CUT ABOVE HERE #################
It's a little bit clumsy this way, but qsub is not really intelligent about handling job specifications (or I am too stupid to figure out how to get it all into one script!), so I ask it to run a shell script.
Best, Darren
Andries van der Leij wrote:
------------------------------------------------------------------------
*From:* Andries van der Leij *Sent:* Wednesday, December 06, 2006 5:59 PM *To:* 'freesurfer@nmr.mgh.harvard.edu' *Subject:* Freesurfer and Grid computing
Dear Freesurfer community,
I?m a PHD student at the university of Amsterdam and I?m currently investigating the possibilities to streamline our MRI data processing stream. Next summer we?ll obtain a research-only scanner. I?m trying
to
push the group to also invest in computing power and am currently investigating the applications that researchers will most probably
use.
I came across a project of the group of Cohen at UCLA. They have configured a Apple (unix) grid and have proposed a more or less
standard
setup specially designed for MRI analyses:
http://airto.bmap.ucla.edu/mt-static/NICluster/archives/2005/06/welcome. html
It is my understanding that one of the members has rewritten the FSL code which allow distributed parallel processing in a Grid. See the benchmarks here:
http://airto.bmap.ucla.edu/bmcweb/bmc_bios/MarkCohen/Apple/Benchmarks.ht m
My question is fairly simple: Are similar steps taken in the
Freesurfer
community? I have no experience with this app myself, but it is my understanding that Freesurfer consumes a lot of resources.
Thank you very much in advance,
Andries van der Leij
------------------------------------------------------------------------
Freesurfer mailing list Freesurfer@nmr.mgh.harvard.edu https://mail.nmr.mgh.harvard.edu/mailman/listinfo/freesurfer
- --
Darren L. Weber, Ph.D. Postdoctoral Scholar
Dynamic Neuroimaging Laboratory, UCSF Department of Radiology, 185 Berry Street, Suite 350, Box 0946, San Francisco, CA 94107, USA.
Tel: +1 415 353-9444 Fax: +1 415 353-9421 www: http://dnl.ucsf.edu/users/dweber
"To explicate the uses of the brain seems as difficult a task as to paint the soul, of which it is commonly said, that it understands all things but itself." Thomas Willis (The Anatomy of the Brain and Nerves, 1664)

Hi,
I asked a question about the parcellation map a couple of days ago. Here is the question again:
The color table for the parcellation is in stats/aparc.annot.ctab, and the labels for surface vertices are in label/lh.aparc.annot. How the vertex vertex label values and the color tables are related each other? Or any way to figure out which parcellation include which vertices? Also, parcellation can be displayed in "outline" mode in tksurfer. Any way to find the outline points quickly? Thank you for your time.
XJ Kang

Hi
actually each .annot file has a color table embedded in it. The parcellation value is packed into an rgb value, and stored for each vertex in the .annot file (r+b<<8+g<<16). There is matlab code to read in the .annots if you want. To find the outline you just find the set of all vertices that have different annot labels from one of their nbrs.
cheers, Bruce
On Wed, 13 Dec 2006, XJ Kang wrote:
Hi,
I asked a question about the parcellation map a couple of days ago. Here is the question again:
The color table for the parcellation is in stats/aparc.annot.ctab, and the labels for surface vertices are in label/lh.aparc.annot. How the vertex vertex label values and the color tables are related each other? Or any way to figure out which parcellation include which vertices? Also, parcellation can be displayed in "outline" mode in tksurfer. Any way to find the outline points quickly? Thank you for your time.
XJ Kang
Freesurfer mailing list Freesurfer@nmr.mgh.harvard.edu https://mail.nmr.mgh.harvard.edu/mailman/listinfo/freesurfer

Hi,
To add to what Bruce just mentioned, for visualization purposes, in tksurfer under the View option bar, choose Label Style and select Outline. This will allow you to visualize where the boundaries of each of the regions of interest are.
Best,
Rahul
On Wed, 13 Dec 2006, Bruce Fischl wrote:
Hi
actually each .annot file has a color table embedded in it. The parcellation value is packed into an rgb value, and stored for each vertex in the .annot file (r+b<<8+g<<16). There is matlab code to read in the .annots if you want. To find the outline you just find the set of all vertices that have different annot labels from one of their nbrs.
cheers, Bruce
On Wed, 13 Dec 2006, XJ Kang wrote:
Hi,
I asked a question about the parcellation map a couple of days ago. Here is the question again:
The color table for the parcellation is in stats/aparc.annot.ctab, and the labels for surface vertices are in label/lh.aparc.annot. How the vertex vertex label values and the color tables are related each other? Or any way to figure out which parcellation include which vertices? Also, parcellation can be displayed in "outline" mode in tksurfer. Any way to find the outline points quickly? Thank you for your time.
XJ Kang
Freesurfer mailing list Freesurfer@nmr.mgh.harvard.edu https://mail.nmr.mgh.harvard.edu/mailman/listinfo/freesurfer
Freesurfer mailing list Freesurfer@nmr.mgh.harvard.edu https://mail.nmr.mgh.harvard.edu/mailman/listinfo/freesurfer
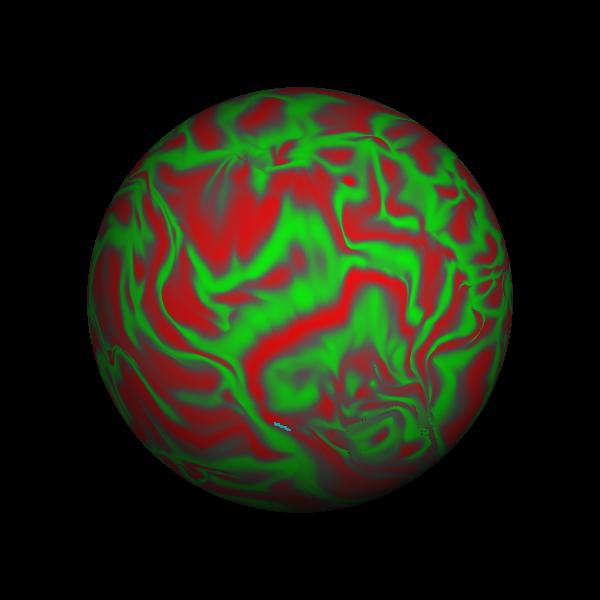
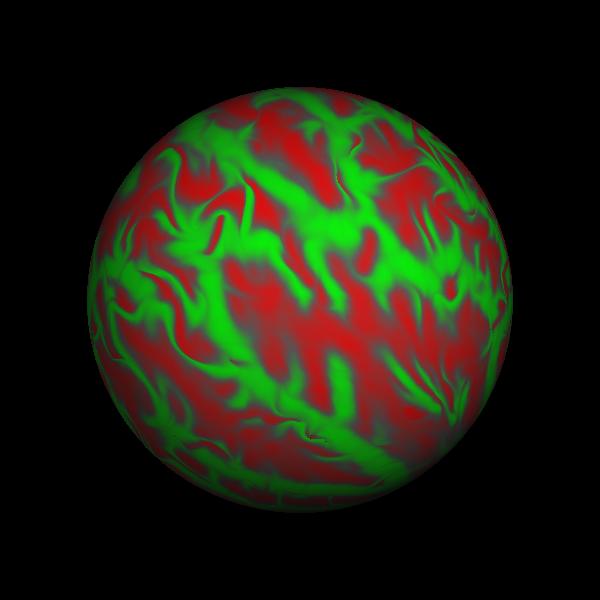
Hi,
I have a question about the spherical registration. As I understand, lh.sphere.reg is the result of registering left hemi to the left template, and lh.rh is left hemi to the right template (reverse registration). While lh.sphere.reg shows clear anatomy structures, lh.rh.sphere.reg seems to mess up the gyral and sulcal structures, as shown in the attached figures. Same thing happened to the right hemisphere, and other subjects.
Anything wrong with the reverse registration? The results are from Freesurfer v-3.0.3. I am not sure if any changes in v3.0.4.
Happy holidays!
XJ Kang
{kind=link}
{kind=link}
{kind=link}
{kind=link}
eek, that one looks completely wrong. I'll try to take a look at this soon, but remind me if you haven't heard anything by the end of the 1st week in Jan.
cheers, Bruce On Fri, 22 Dec 2006, XJ Kang wrote:
Hi,
I have a question about the spherical registration. As I understand, lh.sphere.reg is the result of registering left hemi to the left template, and lh.rh is left hemi to the right template (reverse registration). While lh.sphere.reg shows clear anatomy structures, lh.rh.sphere.reg seems to mess up the gyral and sulcal structures, as shown in the attached figures. Same thing happened to the right hemisphere, and other subjects.
Anything wrong with the reverse registration? The results are from Freesurfer v-3.0.3. I am not sure if any changes in v3.0.4.
Happy holidays!
XJ Kang

BTW, I don't think we've ever had this working. We had talked about doing a straight mapping from one hemi to the other instead of going through the atlas. Christophe wants to do this too.
On Sat, 23 Dec 2006, Bruce Fischl wrote:
eek, that one looks completely wrong. I'll try to take a look at this soon, but remind me if you haven't heard anything by the end of the 1st week in Jan.
cheers, Bruce On Fri, 22 Dec 2006, XJ Kang wrote:
Hi,
I have a question about the spherical registration. As I understand, lh.sphere.reg is the result of registering left hemi to the left template, and lh.rh is left hemi to the right template (reverse registration). While lh.sphere.reg shows clear anatomy structures, lh.rh.sphere.reg seems to mess up the gyral and sulcal structures, as shown in the attached figures. Same thing happened to the right hemisphere, and other subjects.
Anything wrong with the reverse registration? The results are from Freesurfer v-3.0.3. I am not sure if any changes in v3.0.4.
Happy holidays!
XJ Kang
Freesurfer mailing list Freesurfer@nmr.mgh.harvard.edu https://mail.nmr.mgh.harvard.edu/mailman/listinfo/freesurfer
oh, maybe you're right. I'll put it on my todo list.
On Thu, 4 Jan 2007, Doug Greve wrote:
BTW, I don't think we've ever had this working. We had talked about doing a straight mapping from one hemi to the other instead of going through the atlas. Christophe wants to do this too.
On Sat, 23 Dec 2006, Bruce Fischl wrote:
eek, that one looks completely wrong. I'll try to take a look at this soon, but remind me if you haven't heard anything by the end of the 1st week in Jan.
cheers, Bruce On Fri, 22 Dec 2006, XJ Kang wrote:
Hi,
I have a question about the spherical registration. As I understand, lh.sphere.reg is the result of registering left hemi to the left template, and lh.rh is left hemi to the right template (reverse registration). While lh.sphere.reg shows clear anatomy structures, lh.rh.sphere.reg seems to mess up the gyral and sulcal structures, as shown in the attached figures. Same thing happened to the right hemisphere, and other subjects.
Anything wrong with the reverse registration? The results are from Freesurfer v-3.0.3. I am not sure if any changes in v3.0.4.
Happy holidays!
XJ Kang
Freesurfer mailing list Freesurfer@nmr.mgh.harvard.edu https://mail.nmr.mgh.harvard.edu/mailman/listinfo/freesurfer
Hi,
I am trying to genearate average surface curvature map from ?h.sphere.reg.
One way I did is using make_average_subject. I got both volume and surface avareges. I also created a surface using my own method: resample the surface maps ?h.sphere.reg to a common spherical coordinates (th, phi), and calculate the averages of all spheres. The average surface map I got is somewhat different from the result of "make_average_subject". Can somebody tell me the rough procedure of mris_make_average_surface?
As far as I know from the FreeSurfer docs, mris_make_average_surface averages a set of surface coordinates and generate an average surface using Talairach coordinates and spherical transform. For the spherical average, does it resample the individual spheres to a common spherical coordinates and average them?
Thanks.
XJ Kang
it uses a spherical parameterizations (longitude and colatitude) to generate averages, then samples the results onto an icosahedron.
cheers, Bruce On Wed, 31 Jan 2007, XJ Kang wrote:
Hi,
I am trying to genearate average surface curvature map from ?h.sphere.reg.
One way I did is using make_average_subject. I got both volume and surface avareges. I also created a surface using my own method: resample the surface maps ?h.sphere.reg to a common spherical coordinates (th, phi), and calculate the averages of all spheres. The average surface map I got is somewhat different from the result of "make_average_subject". Can somebody tell me the rough procedure of mris_make_average_surface?
As far as I know from the FreeSurfer docs, mris_make_average_surface averages a set of surface coordinates and generate an average surface using Talairach coordinates and spherical transform. For the spherical average, does it resample the individual spheres to a common spherical coordinates and average them?
Thanks.
XJ Kang _______________________________________________ Freesurfer mailing list Freesurfer@nmr.mgh.harvard.edu https://mail.nmr.mgh.harvard.edu/mailman/listinfo/freesurfer
freesurfer@nmr.mgh.harvard.edu
-
 Andries van der Leij
Andries van der Leij -
 Bruce Fischl
Bruce Fischl -
 Darren Weber
Darren Weber -
 Doug Greve
Doug Greve -
 Nick Schmansky
Nick Schmansky -
 Rahul Desikan
Rahul Desikan -
 XJ Kang
XJ Kang