
Greetings,
I've been asked to provide some extra information about GPU support in Freesurfer (being the one guilty of mri_em_register_cuda...).
Firstly, there are no immediate plans for OpenCL support. It would be very nice to have - with ATI, NVIDIA _and_ x86 multicore backends. However, it's far less mature than CUDA. The good news is that the really 'hard' bit is restructuring the algorithms to fit well on a GPU. The syntax of CUDA and OpenCL is very similar (strange that....), but OpenCL is more verbose.
As for cards..... for what is in the current release, any GeForce GTX-200 series or Tesla 10 series (i.e. C1060 and S1070) card should work (I don't know the Quadro model numbers - CUDA architecture 1.3 is the key feature). I think that everything should actually work on somewhat older cards, but the compile flags will have to be tweaked. So long as that threshold is reached, the only issue is the amount of RAM needed. Currently, I expect that any card with at least 1 GiB of RAM will have plenty, and the threshold for mri_em_register_cuda will be much lower than that.
Going forward, I would strongly recommend purchasing 'Fermi' class cards. These are the GTX 400 series, and Tesla 20 series. The new architecture lifts some hardware limits on GPU kernels which are crippling for portions of mri_ca_register. With a more accelerated mri_ca_register, RAM limits may also come into play, until I can come up with a suitably cunning GPU implementation of the Gaussian Classifier Array (right now, I'm going to burn around 2 GiB on a single GCA, to make implementation simple). However, I have bigger fish to fry first.
One final thing: Nick and I found last week that the accelerated mri_em_register_cuda doesn't seem to work prior to skull stripping. I'm going to work on this this week, but if you want to continue using the GPU accelerated binary, you'll have to turn off the FAST_TRANSLATION and FAST_TRANSFORM flags in mri_em_register.c, and recompile. This will increase the runtime to around 4 minutes on ernie, but will give results identical to the CPU code.
I hope this is helpful,
Richard

Hi Richard,
Just to clarify one point: when you mentioned CUDA architecture 1.3 I think you did mean Cuda Computing Capability 1.3
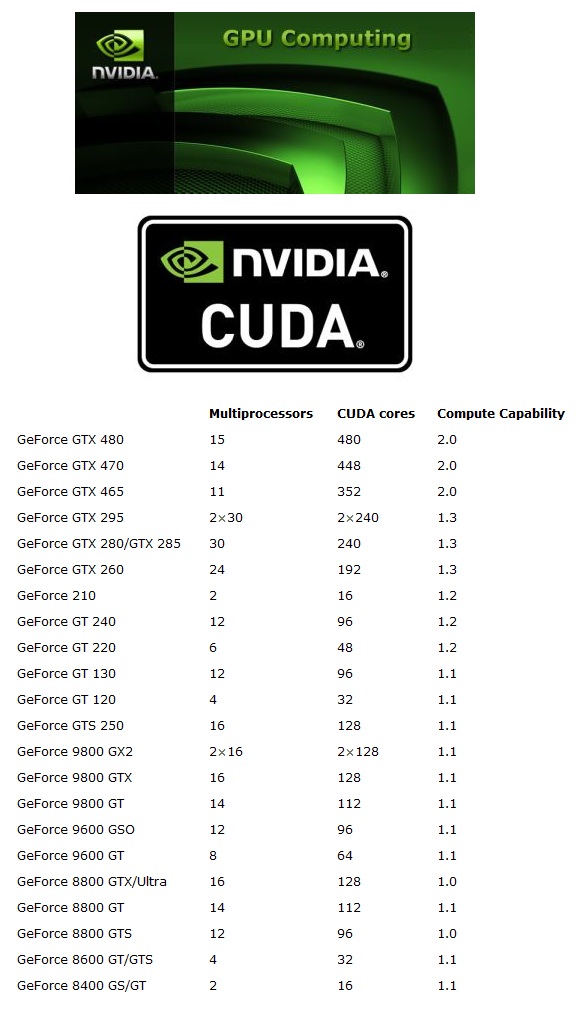
Attached in this e-mail the CUDA Computing Capability for each NVidia GeForce series card so people can figure out weather their board is below the 1.3 threshold.
Also you can use the the freeware GPU Caps Viewer to be sure: http://www.ozone3d.net/gpu_caps_viewer/
* Multiprocessors* *CUDA cores* *Compute Capability* GeForce GTX 480 15 4802.0 GeForce GTX 470 14 448 2.0 GeForce GTX 465 11 352 2.0 GeForce GTX 295 2×30 2×240 1.3 GeForce GTX 280/GTX 285 30 240 1.3 GeForce GTX 260 24 192 1.3 GeForce 210 2 16 1.2 GeForce GT 240 12 96 1.2 GeForce GT 220 6 48 1.2 GeForce GT 130 12 96 1.1 GeForce GT 120 4 32 1.1 GeForce GTS 250 16 128 1.1 GeForce 9800 GX2 2×16 2×128 1.1 GeForce 9800 GTX 16 128 1.1 GeForce 9800 GT 14 112 1.1 GeForce 9600 GSO 12 96 1.1 GeForce 9600 GT 8 64 1.1 GeForce 8800 GTX/Ultra 16 128 1.0 GeForce 8800 GT 14 1121.1 GeForce 8800 GTS 12 96 1.0 GeForce 8600 GT/GTS 4 32 1.1 GeForce 8400 GS/GT 2 16 1.1
Cheers,
PPJ --------------------------------------------------------------------- Pedro Paulo de Magalhães Oliveira Junior Diretor de Operações Netfilter & SpeedComm Telecom -- www.netfilter.com.br -- For mobile: http://www.netfilter.com.br/mobile
On Tue, Aug 24, 2010 at 10:37, Richard G. Edgar rge21@nmr.mgh.harvard.eduwrote:
Greetings,
I've been asked to provide some extra information about GPU support in Freesurfer (being the one guilty of mri_em_register_cuda...).
Firstly, there are no immediate plans for OpenCL support. It would be very nice to have - with ATI, NVIDIA _and_ x86 multicore backends. However, it's far less mature than CUDA. The good news is that the really 'hard' bit is restructuring the algorithms to fit well on a GPU. The syntax of CUDA and OpenCL is very similar (strange that....), but OpenCL is more verbose.
As for cards..... for what is in the current release, any GeForce GTX-200 series or Tesla 10 series (i.e. C1060 and S1070) card should work (I don't know the Quadro model numbers - CUDA architecture 1.3 is the key feature). I think that everything should actually work on somewhat older cards, but the compile flags will have to be tweaked. So long as that threshold is reached, the only issue is the amount of RAM needed. Currently, I expect that any card with at least 1 GiB of RAM will have plenty, and the threshold for mri_em_register_cuda will be much lower than that.
Going forward, I would strongly recommend purchasing 'Fermi' class cards. These are the GTX 400 series, and Tesla 20 series. The new architecture lifts some hardware limits on GPU kernels which are crippling for portions of mri_ca_register. With a more accelerated mri_ca_register, RAM limits may also come into play, until I can come up with a suitably cunning GPU implementation of the Gaussian Classifier Array (right now, I'm going to burn around 2 GiB on a single GCA, to make implementation simple). However, I have bigger fish to fry first.
One final thing: Nick and I found last week that the accelerated mri_em_register_cuda doesn't seem to work prior to skull stripping. I'm going to work on this this week, but if you want to continue using the GPU accelerated binary, you'll have to turn off the FAST_TRANSLATION and FAST_TRANSFORM flags in mri_em_register.c, and recompile. This will increase the runtime to around 4 minutes on ernie, but will give results identical to the CPU code.
I hope this is helpful,
Richard
Freesurfer mailing list Freesurfer@nmr.mgh.harvard.edu https://mail.nmr.mgh.harvard.edu/mailman/listinfo/freesurfer
The information in this e-mail is intended only for the person to whom it is addressed. If you believe this e-mail was sent to you in error and the e-mail contains patient information, please contact the Partners Compliance HelpLine at http://www.partners.org/complianceline . If the e-mail was sent to you in error but does not contain patient information, please contact the sender and properly dispose of the e-mail.
{kind=link}
On Tue, 2010-08-24 at 10:55 -0300, Pedro Paulo de Magalhães Oliveira Junior wrote:
Just to clarify one point: when you mentioned CUDA architecture 1.3 I think you did mean Cuda Computing Capability 1.3
Indeed - it's the -arch flag to the compiler, hence I got mixed up.
We haven't tested this, but I think that any card with compute capability 1.1 will work with the released code, provided the -arch flag is changed. However, I don't have a card to check this, and doing so is not a priority.
Regards,
Richard

since we'll be providing updates to these _cuda binaries (in the form of the fscudabins_linuc_centos4*.tgz tarballs), i'll make sure they are built with the 1.1 architecture in our stable branch.
i'm thinking our plan will be to conform to the 1.1 architecture for the near term stable release _cuda binaries, with internal development targeted at the fermi-class cards. at some point (probably not till next year), we'll make the decision as to which lowest architecture to support, or perhaps we can figure out a way to conditionally compile the code to support multiple architectures. it will be a give-and-take with the cuda user base and us, as we figure out what cards people have, and what architecture elements are essential to make cuda/freesurfer worthwhile.
n.
On Tue, 2010-08-24 at 10:08 -0400, Richard G. Edgar wrote:
On Tue, 2010-08-24 at 10:55 -0300, Pedro Paulo de Magalhães Oliveira Junior wrote:
Just to clarify one point: when you mentioned CUDA architecture 1.3 I think you did mean Cuda Computing Capability 1.3
Indeed - it's the -arch flag to the compiler, hence I got mixed up.
We haven't tested this, but I think that any card with compute capability 1.1 will work with the released code, provided the -arch flag is changed. However, I don't have a card to check this, and doing so is not a priority.
Regards,
Richard
Freesurfer mailing list Freesurfer@nmr.mgh.harvard.edu https://mail.nmr.mgh.harvard.edu/mailman/listinfo/freesurfer
On Tue, 2010-08-24 at 09:37 -0400, Richard G. Edgar wrote:
One final thing: Nick and I found last week that the accelerated mri_em_register_cuda doesn't seem to work prior to skull stripping. I'm going to work on this this week, but if you want to continue using the GPU accelerated binary, you'll have to turn off the FAST_TRANSLATION and FAST_TRANSFORM flags in mri_em_register.c, and recompile. This will increase the runtime to around 4 minutes on ernie, but will give results identical to the CPU code.
Actually, the problems with mri_em_register_cuda appear to be a little more widespread. I'm working on testing this with more brains now (the perils of having only one test case...), and hope to have an update soon.
Regards,
Richard

Hi Richard and others,
allow me one additional remark that may be crucial for those considering to invest in new cards. Although the Fermi class cards make use of the same architecture (Geforce GTX 480 and Tesla C2050 for example), for consumer products (GTX 400 series), double precision performance has been limited to a quarter of that of the "full" Fermi architecture (Tesla C20xx). Error checking and correcting memory (ECC) is also disabled on consumer cards. I don't really know how important double precision is for the CUDA enabled Freesurfer tools, but this could mean you have to buy four GTX cards to catch up with the performance of one Tesla card.
Cheers, Georg
-----Ursprüngliche Nachricht----- Von: freesurfer-bounces@nmr.mgh.harvard.edu [mailto:freesurfer-bounces@nmr.mgh.harvard.edu] Im Auftrag von Richard G. Edgar Gesendet: Dienstag, 24. August 2010 15:38 An: freesurfer@nmr.mgh.harvard.edu Betreff: [Freesurfer] Notes on CUDA Acceleration
Greetings,
I've been asked to provide some extra information about GPU support in Freesurfer (being the one guilty of mri_em_register_cuda...).
Firstly, there are no immediate plans for OpenCL support. It would be very nice to have - with ATI, NVIDIA _and_ x86 multicore backends. However, it's far less mature than CUDA. The good news is that the really 'hard' bit is restructuring the algorithms to fit well on a GPU. The syntax of CUDA and OpenCL is very similar (strange that....), but OpenCL is more verbose.
As for cards..... for what is in the current release, any GeForce GTX-200 series or Tesla 10 series (i.e. C1060 and S1070) card should work (I don't know the Quadro model numbers - CUDA architecture 1.3 is the key feature). I think that everything should actually work on somewhat older cards, but the compile flags will have to be tweaked. So long as that threshold is reached, the only issue is the amount of RAM needed. Currently, I expect that any card with at least 1 GiB of RAM will have plenty, and the threshold for mri_em_register_cuda will be much lower than that.
Going forward, I would strongly recommend purchasing 'Fermi' class cards. These are the GTX 400 series, and Tesla 20 series. The new architecture lifts some hardware limits on GPU kernels which are crippling for portions of mri_ca_register. With a more accelerated mri_ca_register, RAM limits may also come into play, until I can come up with a suitably cunning GPU implementation of the Gaussian Classifier Array (right now, I'm going to burn around 2 GiB on a single GCA, to make implementation simple). However, I have bigger fish to fry first.
One final thing: Nick and I found last week that the accelerated mri_em_register_cuda doesn't seem to work prior to skull stripping. I'm going to work on this this week, but if you want to continue using the GPU accelerated binary, you'll have to turn off the FAST_TRANSLATION and FAST_TRANSFORM flags in mri_em_register.c, and recompile. This will increase the runtime to around 4 minutes on ernie, but will give results identical to the CPU code.
I hope this is helpful,
Richard
_______________________________________________ Freesurfer mailing list Freesurfer@nmr.mgh.harvard.edu https://mail.nmr.mgh.harvard.edu/mailman/listinfo/freesurfer
The information in this e-mail is intended only for the person to whom it is addressed. If you believe this e-mail was sent to you in error and the e-mail contains patient information, please contact the Partners Compliance HelpLine at http://www.partners.org/complianceline . If the e-mail was sent to you in error but does not contain patient information, please contact the sender and properly dispose of the e-mail.
On Thu, 2010-08-26 at 23:23 +0200, Georg Homola wrote:
allow me one additional remark that may be crucial for those considering to invest in new cards. Although the Fermi class cards make use of the same architecture (Geforce GTX 480 and Tesla C2050 for example), for consumer products (GTX 400 series), double precision performance has been limited to a quarter of that of the "full" Fermi architecture (Tesla C20xx). Error checking and correcting memory (ECC) is also disabled on consumer cards. I don't really know how important double precision is for the CUDA enabled Freesurfer tools, but this could mean you have to buy four GTX cards to catch up with the performance of one Tesla card.
This is correct. At the moment, I don't think that I use double precision anywhere, hence we're experimenting with CUDA Capability 1.1. I may have to start using double precision, given the problems which have just been found with mri_em_register_cuda. However, I'm not sure what the performance impact of the degraded GeForce performance will be. I'm reasonably certain that most of the code is bandwidth bound, so if anything a GeForce will outpace a Tesla, even if it uses double precision.
Of greater concern is the amount of memory available. The Tesla cards have quite a bit more RAM. This is likely to become important in the near future, as I work to get the rest of the mri_ca_register pipeline onto the GPU - the GCA structure is quite sparse, but for the initial port, I'll burn RAM instead of coming up with a cunning packing method. There will be enough to debug without worrying about optimisation.
Regards,
Richard

Richard, Nick, Pedro, & the Freesurfers,
I am looking at choice of the lower end fermi cards and I was wondering if you could comment of Freesurfer's ability to take advantage of some seldom used functions included in nVidia GTX 400 (including tesselation) that were stripped down from nVidia GF104 chipset.
GeForce GTX 465 has the "original" nVidia GTX 400 chip and GeForce GTX 460 has the "revised" GF104 chipset. Some claim that the revision in the chipset is geared towards cheaper manufacturing. Unfortunately benchmarks for those cards are usually aimed at gaming performance that is not of my interest.
http://www.gpureview.com/show_cards.php?card1=632&card2=631
Greetings,
Jacek
Jacek,
A 465 will do well, try to grab as much memory as possible in de video board. AFAIK, FreeSurfer will return to compute capabilities 1.1 so you won't need a fermi architeture.
cheers --------------------------------------------------------------------- Pedro Paulo de Magalhães Oliveira Junior Diretor de Operações Netfilter & SpeedComm Telecom -- www.netfilter.com.br -- For mobile: http://www.netfilter.com.br/mobile
On Fri, Aug 27, 2010 at 19:37, Freesurfer Local Archive < freesurfer@jonca.org> wrote:
Richard, Nick, Pedro, & the Freesurfers,
I am looking at choice of the lower end fermi cards and I was wondering if you could comment of Freesurfer's ability to take advantage of some seldom used functions included in nVidia GTX 400 (including tesselation) that were stripped down from nVidia GF104 chipset.
GeForce GTX 465 has the "original" nVidia GTX 400 chip and GeForce GTX 460 has the "revised" GF104 chipset. Some claim that the revision in the chipset is geared towards cheaper manufacturing. Unfortunately benchmarks for those cards are usually aimed at gaming performance that is not of my interest.
http://www.gpureview.com/show_cards.php?card1=632&card2=631
Greetings,
Jacek _______________________________________________ Freesurfer mailing list Freesurfer@nmr.mgh.harvard.edu https://mail.nmr.mgh.harvard.edu/mailman/listinfo/freesurfer
The information in this e-mail is intended only for the person to whom it is addressed. If you believe this e-mail was sent to you in error and the e-mail contains patient information, please contact the Partners Compliance HelpLine at http://www.partners.org/complianceline . If the e-mail was sent to you in error but does not contain patient information, please contact the sender and properly dispose of the e-mail.
On Fri, 2010-08-27 at 17:37 -0500, Freesurfer Local Archive wrote:
I am looking at choice of the lower end fermi cards and I was wondering if you could comment of Freesurfer's ability to take advantage of some seldom used functions included in nVidia GTX 400 (including tesselation) that were stripped down from nVidia GF104 chipset.
I'm not aware of any issues with these cards which affect CUDA. In most cases, the primary bottleneck in my ports is the rearrangement of data for the GPU, so the card itself is less important (provided it has enough RAM). As another reply said, right now, we're targetting CUDA Compute 1.1, which is substantially pre-Fermi.
Regards,
Richard
freesurfer@nmr.mgh.harvard.edu
-
 Freesurfer Local Archive
Freesurfer Local Archive -
 Georg Homola
Georg Homola -
 Nick Schmansky
Nick Schmansky -
 Pedro Paulo de Magalhães Oliveira Junior
Pedro Paulo de Magalhães Oliveira Junior -
 Richard G. Edgar
Richard G. Edgar